A tiny live LLM coded from scratch and trained on books from François René de Chateaubriand.
René the boozer, the yarn from beyond the grave...
Introduction
As a physics graduate in 2026, I’ve to accept a simple reality: if you want a job, you’d better know some machine learning. So here I am.
This article, René the Boozer, explores what has become a common rite of passage: training a LLM on books of a long-dead author. I built it from scratch to understand what actually hides behind the transformer hype. The model is trained on texts by François-René de Chateaubriand, my favorite novelists, and runs here in a live, streamed version.
The model only speaks French (the language of love), so it is completely normal if some of you don’t understand it. Consider it as my modest contribution to the long-standing tradition of English bashing in my beloved french culture.
Since the live model runs on limited resources, it is far from perfect. But as an avid reader of the original René, I can guarantee that it sometimes captures his typical style of writting. The rest of the time, it sounds more like a René after a few drinks...
Silence ! René the boozer is speaking !
Chateaubriand (simply the best !)
If you know me personally, you’ve probably already heard me talk about Chateaubriand. He is, according to the highest literary authorities (Victor Hugo and me), one of the greatest French writers.
He lived through one of the most unstable periods in French history; the Revolution, the Empire, and the Restoration. He experienced many lives, each exceptional on its own: a noble caught in a revolution, an explorer in the New World, a soldier, a writer, and later a politician. He is even one of the introducers of Romanticism in France, shaping a literary movement that would influence generations of writers.
His prose can be heavy at times, but it is also among the most epic. His novels may feel somewhat outdated today, but his Memoirs from Beyond the Grave remains one of the most majestic works in French literature, where he narates his tumultuous life and develops remarkably visionary reflections.
Read it.
Since I have a special attachment to his work (see my Mediterranean Itinerary), I decided to train my LLM on his books..
LLM
Following the small course by Karpathy and talking a lot with ChatGPT, I coded my LLM entirely from scratch. After getting comfortable with PyTorch, I started rebuilding the classic GPT-2 architecture using my own homemade transformers.
The current version is quite simple: it uses single-character tokenization, a naive positional embedding, and Multi-Head Attention. The architecture of the streamed version looks like this:
Architecture
GPT(
(embedding): EmbeddingLayer(
(E): Embedding(65, 384)
(P): Embedding(128, 384)
)
(transformer_blocks): ModuleList(
(0-5): 6 x TransformerLayer(
(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(attention): MultiHeadAttention(
(Wq): Linear(in_features=384, out_features=384, bias=False)
(Wk): Linear(in_features=384, out_features=384, bias=False)
(Wv): Linear(in_features=384, out_features=384, bias=False)
(Wo): Linear(in_features=384, out_features=384, bias=False)
)
(feed_forward): FeedForwardLayer(
(NN): Sequential(
(0): Linear(in_features=384, out_features=1536, bias=True)
(1): GELU(approximate='none')
(2): Linear(in_features=1536, out_features=384, bias=True)
)
)
)
)
(final_norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(linear_head): Linear(in_features=384, out_features=65, bias=False)
)Key details:
- Vocabulary size: 65
- Embedding dimension: 384
- Context window: 128
- Transformer: 6 layers, each with 4 attention heads and a 4× expansion factor in the feedforward network
- Total parameters: 10,737,408
Dataset
I used 11,473,626 tokens from Chateaubriand. The dataset was built by sliding a context window of 128 characters across the text with a shift of 1 character, and forming shuffled batches of 64 (roughly the same number as the total tokens).
Training
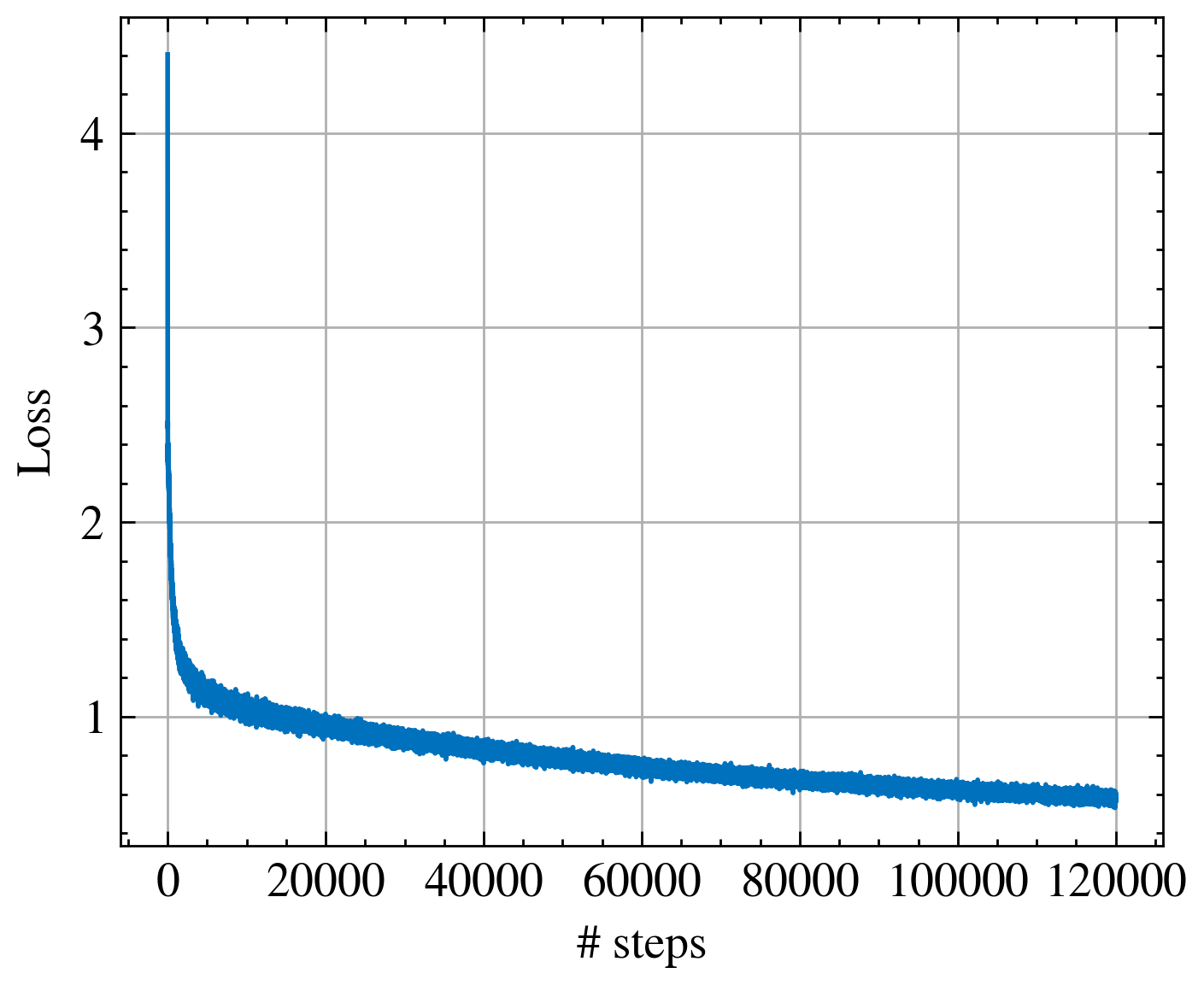
For the training part I use the Adam optimizer and the cross entropy loss.
torch.optim.Adam(self.model.parameters(), lr=3e-4)I trained for only 10% of an epoch, with 120,000 steps, which took about 8 hours on my personal computer GPU.
Inference
I used top-k sampling (k=5) with a temperature of 1, which gave acceptable performance for real-time text generation.
API and Websocket
This project turned into a little adventure into parts of computing I had never explored before. I wanted you, my friend, to be able to interact with my LLM in real time, so I made it stream its output as it wrote, all running on a small VPS.
What started as a small experiment quickly became a rabbit hole: I ended up building almost a whole mini-project on top of it to make server setup easier: my server-toolbox project.
Now, the LLM runs on a dedicated CPU, behind an Nginx proxy, while a FastAPI backend keeps the WebSocket connection open, letting you watch the model type its thoughts letter by letter. It’s like a tiny orchestra of servers and code, all working together to bring the model to life !
Outlooks
- Improve positional embedding (RoPE)
- Improve tokenization
- ...